
728x90
❓ 더 맵게
🏷️ 관련 주제 : 힙

💦 나의 시도
PriorityQueue와 재귀함수를 이용한 풀이
음식을 섞을 때, 가장 맵지 않은 두 스코빌 지수의 음식을 섞으므로
음식을 섞은 후에 항상 정렬이 되어 있어야 할 필요가 있다고 생각하였습니다.
따라서 매번 정렬을 하는 것보다 PriorityQueue를 사용하는 것이 더 적절하다고 판단하여 PriorityQueue를 스코빌 지수를 담을 자료구조로 선택하였습니다.
그리고 재귀함수를 통해 결과값을 반환하도록 하였습니다.
- PriorityQueue
heap내의 원소 개수가 2개 미만이면 음식을 섞을 수 없으므로 -1을 반환하도록 하였습니다. heap의 크기가 2 이상이면 음식을 섞을 수 있으므로 음식을 섞은 횟수 intmixCnt를 1 증가 시키고heap에서 두 원소를 꺼내 새로운 스코빌 지수 inthot을 구하였습니다.hot을heap에 추가하고heap안에서 가장 최솟값인 맨 앞의 원소가K이상이면 모든 음식의 스코빌 지수가K이상이 된 것이므로mixCnt를 반환- 그렇지 않으면 다시
makeHot()함수를 호출하도록 하였습니다.
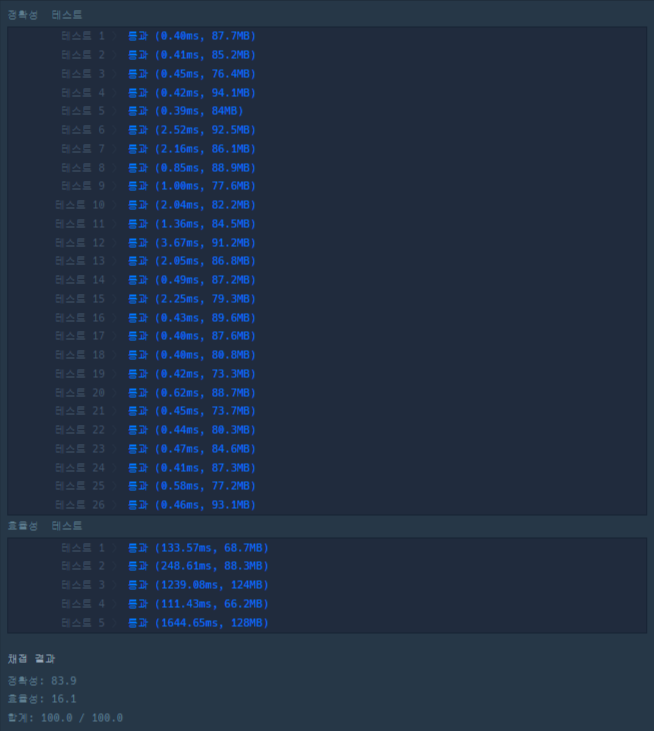
이렇게 제출한 결과 정확성 테스트에서 1문제가 틀린 값이 나왔습니다.
생각을 해 보니 모든 음식이 이미 스코빌 지수 K 이상인 경우가 존재하므로 solution() 메서드 안에서 heap.peek()가 K 이상인 경우 0을 반환하도록 하였습니다.
이 때 제출한 코드
import java.util.*;
class Solution {
public int solution(int[] scoville, int K) {
PriorityQueue heap = new PriorityQueue(Comparator.naturalOrder());
for (int n : scoville) {
heap.offer(n);
}
if (heap.peek() >= K) {
return 0;
}
return makeHot(heap, 0, K);
}
public int makeHot(PriorityQueue heap, int mixCnt, int K) {
if (heap.size() < 2) {
return -1;
}
mixCnt++;
int h1 = heap.poll();
int h2 = heap.poll();
int hot = h1 + (h2 * 2);
heap.offer(hot);
if (heap.peek() >= K) {
return mixCnt;
}
return makeHot(heap, mixCnt, K);
}
}💥 효율성 테스트 실패(런타임 에러)
이제는 제출 성공할 것이라 생각했건만...
효율성 테스트에서 런타임 에러가 발생하였습니다.
무엇이 문제일지 고민해 본 결과 재귀함수를 호출하여 그런 것이라 판단하여 재귀함수 호출하는 대신 반복문을 통해 음식을 섞는 과정을 반복하여 그 결과값을 반환하도록 하였습니다.

그 결과 성공적으로 효율성 테스트도 통과할 수 있었습니다.
📑제출 기록 및 오답 원인

💯 해결 방법
import java.util.*;
class Solution {
public int solution(int[] scoville, int K) {
PriorityQueue<Integer> heap = new PriorityQueue(Comparator.naturalOrder());
for (int n : scoville) {
heap.offer(n);
}
if (heap.peek() >= K) {
return 0;
}
int mixCnt = 0;
while (heap.size() >= 2) {
mixCnt++;
int h1 = heap.poll();
int h2 = heap.poll();
int hot = h1 + (h2 * 2);
heap.offer(hot);
if (heap.peek() >= K) {
return mixCnt;
}
}
return -1;
}
}📝 공부한 내용
힙(Heap)
완전 이진 트리의 일종으로 우선순위 큐를 위하여 만들어진 자료구조
- 여러 개의 값들 중에서 최댓값이나 최솟값을 빠르게 찾아내도록 만들어진 자료구조
- 일종의 반정렬 상태(느슨한 정렬 상태)를 유지한다.
- 큰 값이 상위 레벨에 있고 작은 값이 하위 레벨에 있다.
부모 노드의 키 값>자식 노드의 키 값(혹은 반대)- 힙 트리에서는 중복된 값을 허용 (이진 탐색 트리에서는 중복된 값을 허용하지 않는다.)
힙(Heap)의 종류
- 최대 힙(max heap)
부모 노드의 키 값$\geq$자식 노드의 키 값
- 최소 힙(min heap)
부모 노드의 키 값$\leq$자식 노드의 키 값
구현
- 힙을 저장하는 표준적인 자료구조는 배열
- 구현을 쉽게 하기 위하여 배열의 첫 번째 인덱스인 0은 사용되지 않는다.
- 특정 위치의 노드 번호는 새로운 노드가 추가되어도 변하지 않는다.
- 힙에서 부모 노드와 자식 노드의 관계
왼쪽 자식의 인덱스=부모 인덱스* 2오른쪽 자식의 인덱스=부모 인덱스* 2 + 1부모의 인덱스=자식의 인덱스/ 2

힙의 삽입
최대 힙(max heap)에 새로운 노드를 삽입해 보자.
- 인덱스 순으로 가장 마지막 위치에 이어서 새로운 요소를 삽입
부모 노드<삽입 노드이면 부모 노드와 삽입 노드를 교환

힙의 삭제
최대 힙(max heap)에서 삭제를 해보자.
최대 힙에서 삭제 연산은 최댓값을 가진 요소를 삭제한다.
- 최대 힙에서 최댓값은 루트 노드이므로 루트 노드가 삭제된다.
- 삭제된 루트 노드에는 힙의 마지막 노드를 가져온다.
- 루트 노드와 자식 노드를 비교하며 힙을 재구성한다.
- 두 자식 노드보다 부모 노드가 작은 경우, 부모 노드는 더 큰 값이 되어야 하므로
두 자식 노드 중 더 큰 값과 부모 노드를 교환한다.
- 두 자식 노드보다 부모 노드가 작은 경우, 부모 노드는 더 큰 값이 되어야 하므로

🏷️ 문제 풀면서 참고한 블로그
728x90




